
Wenn du LoRA-Training und volle Kontrolle willst, aber die Hardware-Hürde von Flux scheust — oder einfach das günstigste Modell mit guter Qualität suchst — dann ist Qwen Image dein Weg. Bei rund 0,008 € pro Bild via API oder kostenlos beim Self-Hosting schlägt es jedes andere Top-Modell preislich.
Qwen Image ist Alibabas open-weights Antwort auf Flux Dev: vollständig gewichts-offen, LoRA-trainierbar, lokal lauffähig, und in vielen Distributionen unter Apache 2.0 lizenziert. Im Markt der Top-Modelle für KI-Influencer ist Qwen das Preis-Leistungs-Wunder — du bekommst eine Qualität, die in vielen Szenarien fast an Flux herankommt, zahlst aber einen Bruchteil des Preises und brauchst weniger VRAM für lokales Self-Hosting.
Diese Anleitung führt dich durch alles: die Position von Qwen im Modell-Vergleich, die fünf Zugangswege (Web, API, Self-Hosting, Cloud-GPU, Managed Drittplattformen), den ersten API-Call, das ComfyUI-Setup, eigenes LoRA-Training, fünf erprobte Prompt-Templates und einen direkten Vergleich mit Flux. Wer für seine Qwen-Pipeline gleich mit dutzenden vorgefertigten Vorlagen starten möchte, findet in unserer Prompt-Matrix mit über 40 Vorlagen die passende Auswahl — sortiert nach Studio-Portrait, Lifestyle-Szene, Outfit-Wechsel und LoRA-kompatibler Prompt-Struktur. Wenn du noch nicht weißt, welches Modell für deinen KI-Influencer das richtige ist, lies erst unseren Vergleich der besten KI-Bildmodelle — und komm dann hierher zurück, wenn du Qwen ernsthaft testen willst.
Was Qwen Image ist
Qwen Image ist ein Text-zu-Bild-Modell aus dem Qwen-Team von Alibaba Cloud — derselben Forschungsgruppe, die auch hinter den Qwen-LLMs steht. Während Alibaba zunächst vor allem für seine Sprachmodelle bekannt war, hat das Team Ende 2025 mit Qwen Image ein Bildmodell veröffentlicht, das direkt in die Top-Liga zielt: vergleichbare Qualität wie Flux Dev, aber mit aggressiverer Open-Source-Strategie und deutlich günstigerer API.
Die Positionierung ist klar: Qwen ist der open-weights Konkurrent zu Flux Dev. Beide Modelle erlauben lokales Self-Hosting, beide sind LoRA-trainierbar, beide haben keine harten Content-Filter im Open-Weights-Build. Der Unterschied liegt im Preis (Qwen ist deutlich günstiger), den Hardware-Anforderungen (Qwen läuft auf weniger VRAM) und der Bildqualität (Flux liegt noch leicht vorn, Qwen schließt aber jede Generation auf).
Im Vergleich zu seinen Top-7-Geschwistern hat Qwen ein klares Profil: kein Plug-and-Play wie Nano Banana 2, kein Speed-Spezialist wie Seedream 4, kein Text-in-Bild wie Ideogram — sondern maximale Kosten-Effizienz und Open-Weights-Freiheit für skalierte Workflows.
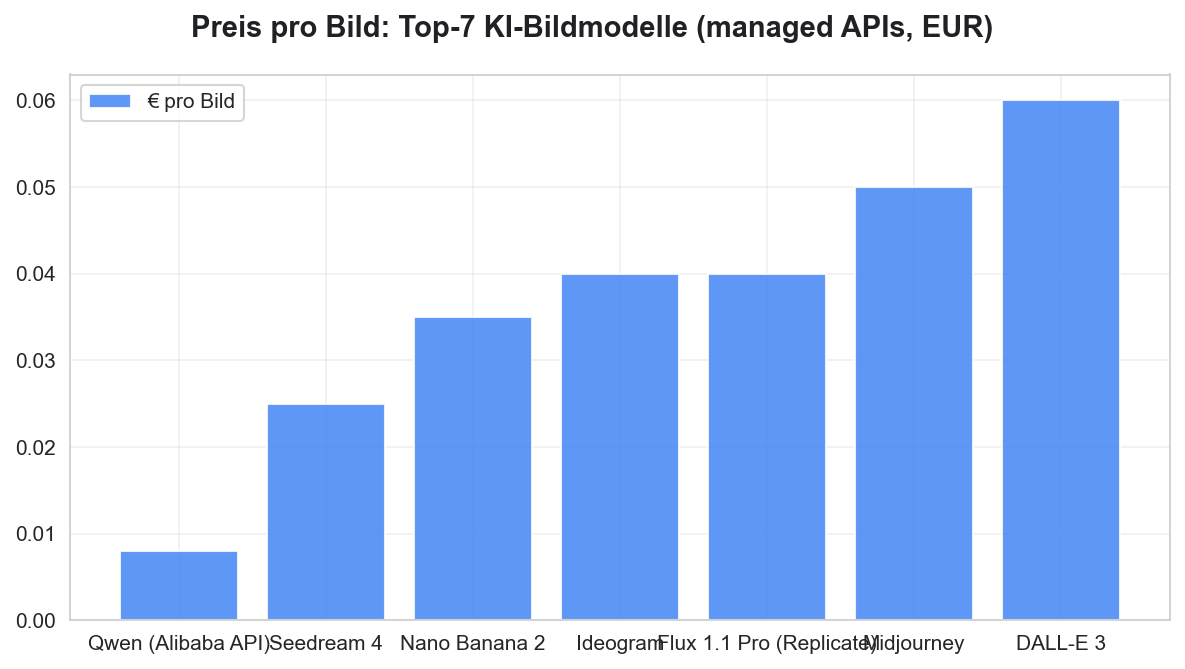
Wie groß der Preis-Vorteil ist, zeigt der direkte Vergleich der Managed-API-Preise: Qwen liegt mit rund 0,008 € pro Bild deutlich unter allen anderen Top-7-Modellen — und beim Self-Hosting fallen die Kosten komplett weg.
Voraussetzungen & Zugang
Du kannst Qwen Image auf fünf verschiedenen Wegen nutzen, je nachdem wie viel Setup du investieren willst und wie viel Kontrolle du brauchst.
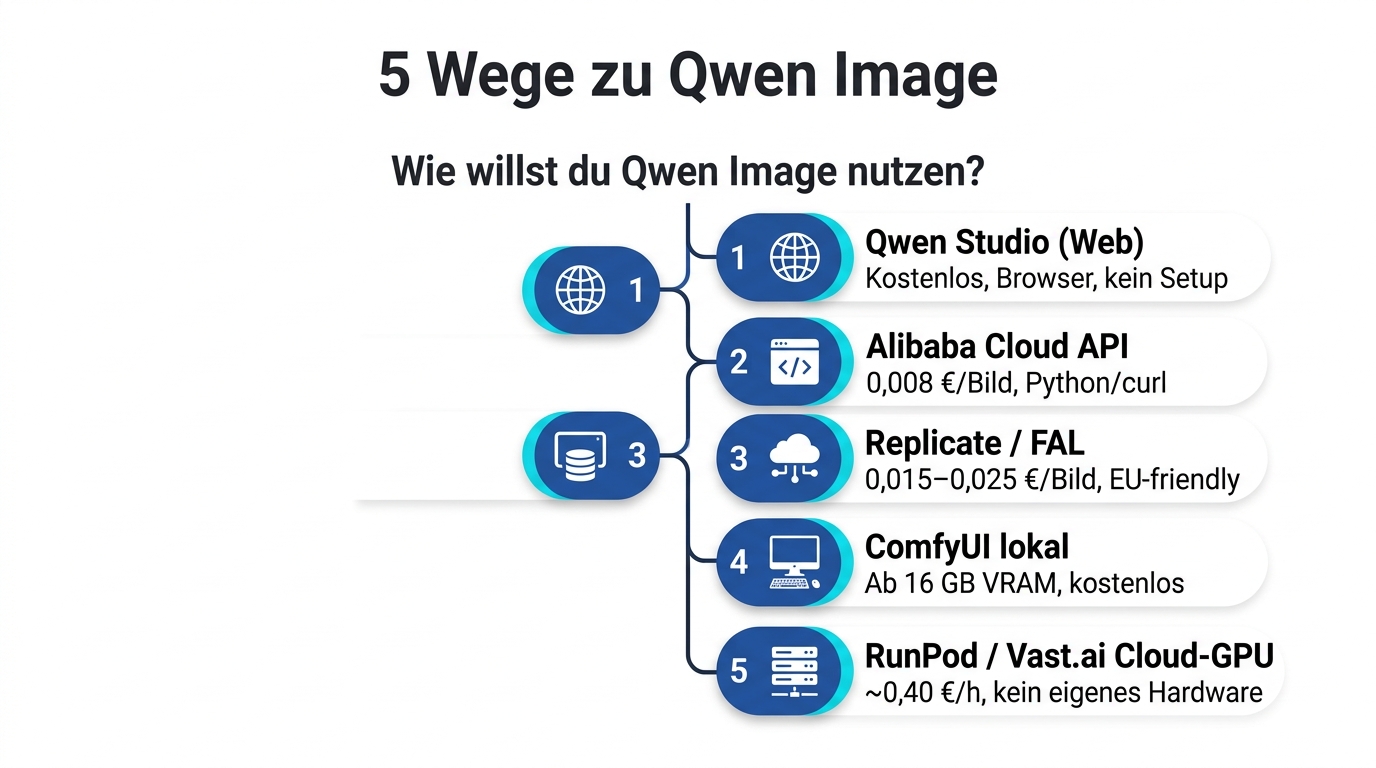
Qwen Studio (qwen.ai) ist der Web-Einstieg — kostenlos, ohne Account-Hürde, ideal um die Qualität in zwei Minuten zu testen. Du tippst einen Prompt, bekommst ein Bild, fertig. Limit: keine API-Kontrolle, keine LoRAs, kein Batch.
Qwen API via Alibaba Cloud ist der schnellste Weg in die Produktion. Du registrierst dich bei Alibaba Cloud, holst dir einen API-Key, und zahlst rund 0,008 € pro Bild — etwa fünfmal günstiger als Flux 1.1 Pro auf Replicate. Für 1.000 Bilder zahlst du also nur etwa 8 €. Das macht Qwen zur ersten Wahl, wenn du eine Posting-Pipeline mit hohem Volumen betreibst.
HuggingFace Download ist der Weg für Self-Hosting-Profis. Die Open-Weights stehen unter Apache 2.0 (in den meisten Distributionen) frei zum Download bereit. Du lädst die Modelldateien (rund 14–18 GB) in deine ComfyUI-Installation und generierst lokal — ohne laufende Kosten, ohne Filter, mit voller Kontrolle.
Replicate / FAL sind die Managed-Drittplattformen. Etwas teurer als die Alibaba-API direkt (rund 0,015–0,025 € pro Bild), dafür mit besserem Developer-Tooling, einfacher Abrechnung in Euro und meist ohne China-Cloud-Setup-Hürden. Für viele europäische Teams der pragmatischste Weg.
ComfyUI Self-Hosting ist der Pro-Pfad — analog zum Flux-Workflow. Du installierst ComfyUI, lädst das Qwen-Modell, lädst optional eigene LoRAs und generierst lokal oder auf einer Cloud-GPU bei RunPod. Hardware-Anforderung: ab 16 GB VRAM läuft Qwen sauber, mit 24 GB hast du Reserve für LoRA-Training. Damit ist Qwen für Self-Hosting deutlich zugänglicher als Flux Dev, das in der Regel 24 GB VRAM voraussetzt.
Pricing & Hardware im Überblick:
- Qwen Studio (Web): kostenlos, kein Setup
- Qwen API (Alibaba Cloud): ~0,008 €/Bild, kein Setup
- Replicate / FAL: ~0,015–0,025 €/Bild, kein Setup
- Self-Hosting lokal: 0 € pro Bild, ab 16 GB VRAM
- Self-Hosting RunPod: ~0,30–0,50 €/h GPU-Miete, A40 oder L40 reichen aus
Eine Übersicht über alle Plattformen, die Qwen, Flux und Co. integrieren, findest du in unserer Liste der besten KI-Bildgeneratoren für AI Influencer.
Schritt-für-Schritt: Erstes Bild via API
Der schnellste produktive Weg führt über die Alibaba-Cloud-API. So kommst du in unter 15 Minuten zum ersten Bild.
1. Account & API-Key holen. Registriere dich bei Alibaba Cloud (alibabacloud.com), aktiviere den Model Studio-Service (heißt teilweise auch DashScope), und generiere im Dashboard einen API-Key. Lege ihn lokal in einer .env-Datei ab — niemals direkt in den Code committen.
2. Erstes API-Call mit Python. Mit drei Zeilen Code generierst du dein erstes Bild:
import os, requests
API_KEY = os.environ["QWEN_API_KEY"]
url = "https://dashscope.aliyuncs.com/api/v1/services/aigc/text2image/image-synthesis"
payload = {
"model": "qwen-image",
"input": {"prompt": "Photorealistic portrait of a 25-year-old woman, soft natural light, Berlin café, cinematic"},
"parameters": {"size": "1024*1024", "n": 1}
}
headers = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}
response = requests.post(url, json=payload, headers=headers)
print(response.json())
Die Antwort enthält eine URL zum generierten Bild — das du herunterladen und weiterverarbeiten kannst. Genauso einfach geht es per curl aus dem Terminal.
3. Reference-Image hochladen. Für Charakter-Konsistenz kannst du ein Referenzbild im Payload mitschicken (Feld ref_img oder reference_image, je nach Endpoint-Version). Qwen versucht dann, Gesichtszüge und Stil aus dem Referenzbild in das neue Bild zu übertragen. Für echte 90 %-Konsistenz reicht das nicht — dafür brauchst du ein eigenes LoRA, dazu gleich mehr. Welche weiteren Hebel es neben Reference-Image und LoRA gibt (Seed-Lock, PuLID, ControlNet) und welche davon mit Qwen sauber spielen, steht in unserer Sammlung der Charakter-Konsistenz-Techniken.
4. Variationen generieren. Setze den Parameter n auf 4 oder 8, um mehrere Varianten desselben Prompts in einem Call zu bekommen. Bei 0,008 € pro Bild kostet ein 8er-Batch nur rund 6 Cent — perfekt für schnelles Iterieren am Prompt.
Self-Hosting mit ComfyUI
Wenn du regelmäßig generierst, eigene LoRAs trainierst oder ohne Filter und ohne API-Kosten arbeiten willst, lohnt sich Self-Hosting. ComfyUI ist die Standard-Oberfläche dafür — node-basiert, Open Source, identische Bedienlogik wie beim Flux-Setup.
Hardware-Anforderungen. Qwen läuft sauber ab 16 GB VRAM — das umfasst Karten wie die RTX 4080, RTX 3090 oder die ältere RTX 2080 Ti. Für LoRA-Training willst du eher 24 GB (RTX 3090 oder 4090). Der entscheidende Vorteil gegenüber Flux Dev: Qwen ist auf Mid-Range-Hardware nutzbar, während Flux Dev oft nur mit 24-GB-Karten zuverlässig läuft. Wenn du eine 16-GB-Karte hast, ist Qwen wahrscheinlich dein einziger Self-Hosting-Pfad in die Top-7.
Model-Download von HuggingFace. Suche auf huggingface.co nach Qwen/Qwen-Image (oder einer aktuellen Distribution wie Qwen-Image-FP8 für niedrigeren VRAM-Verbrauch). Lade die Modelldateien (rund 14–18 GB) und kopiere sie in ComfyUI/models/checkpoints/. Falls eine separate VAE oder ein Text-Encoder mitgeliefert wird, gehören die nach ComfyUI/models/vae/ bzw. ComfyUI/models/clip/.
ComfyUI-Setup-Schritte. Wenn du noch keine ComfyUI-Installation hast, lies unsere ComfyUI-Anleitung für Flux — die Installations-Schritte sind identisch (Git Clone, Python-Venv, pip install -r requirements.txt, Start mit python main.py). Für Qwen brauchst du danach nur einen passenden Workflow — die Qwen-Community auf GitHub und Reddit teilt JSON-Workflows, die du per Drag & Drop in ComfyUI laden kannst.
Erste lokale Generierung. Lade den Qwen-Workflow, trage deinen Prompt im Text-Encoder-Node ein, klicke „Queue Prompt“. Das erste Bild dauert je nach GPU 8–25 Sekunden, danach ist das Modell im VRAM gecacht und es geht schneller.
Cloud-Alternative: RunPod / Vast.ai. Wenn du keine eigene GPU hast, miete eine bei RunPod oder Vast.ai. Wähle ein vorgefertigtes ComfyUI-Template, starte eine A40 oder L40 (rund 0,35–0,50 € pro Stunde), greife per Browser auf das Interface zu. Wenn du die Instanz nach der Session ausschaltest, zahlst du nur ~0,02 €/h für persistenten Storage. Bei 30 Stunden Nutzung im Monat sind das etwa 12 € — günstiger als die meisten Managed-Plattformen, ohne Filter, mit voller LoRA-Kontrolle.
LoRA-Training für deinen KI-Charakter
Ein LoRA (Low-Rank Adaptation) ist eine kleine Zusatzdatei (50–200 MB), die dem Basismodell beibringt, einen bestimmten Charakter, Stil oder Look zu reproduzieren. Ohne LoRA erreicht Qwen rund 60 % Charakter-Konsistenz über mehrere Bilder; mit gut trainiertem LoRA sind es 88–93 %. Die ausführliche Theorie hinter LoRAs (Trainings-Daten-Sammlung, Captioning, Hyperparameter) haben wir bereits im Flux-LoRA-Workflow erklärt — die Konzepte gelten 1:1 auch für Qwen.
Tools für Qwen-LoRA-Training:
- AI-Toolkit (Ostris) — der De-facto-Standard. Open Source, unterstützt Qwen seit Anfang 2026, läuft auf 24 GB VRAM. Konfiguration via YAML-Datei, Training läuft per
python run.py config.yaml. - kohya_ss — die etablierte SD/Flux-LoRA-Lösung mit Web-UI. Hat seit Q1 2026 offiziellen Qwen-Support. Etwas mehr Klick-Aufwand, dafür sehr stabile Trainingsläufe.
- fal.ai LoRA-Trainer — wenn du keine Hardware hast: Lade 15–25 Bilder hoch, wähle „Qwen Image LoRA“, zahlst rund 3–5 € pro Trainingslauf, bekommst nach 30–60 Minuten eine
.safetensors-Datei.
Training-Parameter (Startwerte):
- Steps: 1.500–2.500 (bei 20 Trainings-Bildern)
- Learning Rate: 1e-4 (linear oder cosine schedule)
- Batch Size: 1–2 (je nach VRAM)
- Trigger-Word: ein einprägsamer Token wie
lara_v1oderxchar1, den du in jeden späteren Prompt einbaust
Wo LoRA speichern und laden. Nach dem Training bekommst du eine .safetensors-Datei. Lege sie in ComfyUI/models/loras/ ab. Im Workflow ziehst du den LoRA-Loader-Node ein und wählst dein neues LoRA aus. Im Prompt referenzierst du dann das Trigger-Word — z. B. portrait of lara_v1, golden hour, Berlin rooftop.
Wenn du tiefer in die LoRA-Theorie einsteigen willst (Captioning-Strategien, Overfitting vermeiden, Daten-Augmentation), lies unseren ausführlichen Flux-LoRA-Guide — die Methoden übertragen sich direkt auf Qwen. Für eine modell-unabhängige, reine Trainings-Anleitung mit Civitai-Datensätzen und kostengünstigem Self-Hosting-Pfad lohnt sich parallel FluxGym & Civitai Schritt-für-Schritt — der Workflow läuft 1:1 für Qwen-LoRAs durch.
5 Prompt-Templates für Qwen Image
Diese Templates sind getestet und liefern bei Qwen direkt brauchbare Ergebnisse. Ersetze lara_v1 durch dein eigenes Trigger-Word, sobald du ein LoRA hast.
1. Lifestyle Portrait:
photorealistic portrait of lara_v1, 25-year-old woman, sitting in a Berlin café,
soft window light, holding a cappuccino, casual cream sweater, natural makeup,
shallow depth of field, shot on 50mm f/1.4, cinematic warm tones
2. Studio Fashion:
high-fashion editorial photo of lara_v1, full body, oversized beige blazer,
minimalist white studio backdrop, soft beauty-dish lighting, confident pose,
shot on 85mm f/2.0, Vogue-style composition, sharp focus on face
3. Outdoor / Travel:
lara_v1 standing at a Lisbon rooftop overlooking pastel buildings, golden hour,
flowing white linen dress, wind in hair, candid laughing expression,
travel-magazine aesthetic, shot on 35mm, soft sun flare
4. High-Volume Product Shot:
lara_v1 holding a [PRODUCT] in front of a clean pastel background,
soft even studio light, friendly smile, eye contact with camera,
e-commerce composition, ample copy space on the right
5. Diverse Ethnicity Portrait:
photorealistic portrait of a 28-year-old woman with afro-textured hair and warm
brown skin, soft natural light, terracotta wall background, minimal jewelry,
authentic relaxed expression, shot on 50mm f/1.8, editorial color grading
Qwen vs. Flux: Wann was?
Für Marken mit strengem Lizenz- und Transparenzbedarf ist außerdem der Adobe Firefly Test relevant.
Wenn dir einfache Bedienung wichtiger ist als Self-Hosting, ist Midjourney für AI Influencer die praktischere Alternative.
Qwen und Flux sind die beiden ernstzunehmenden Open-Weights-Optionen im Top-7-Feld. Welches Modell für dich besser ist, hängt von vier Faktoren ab.
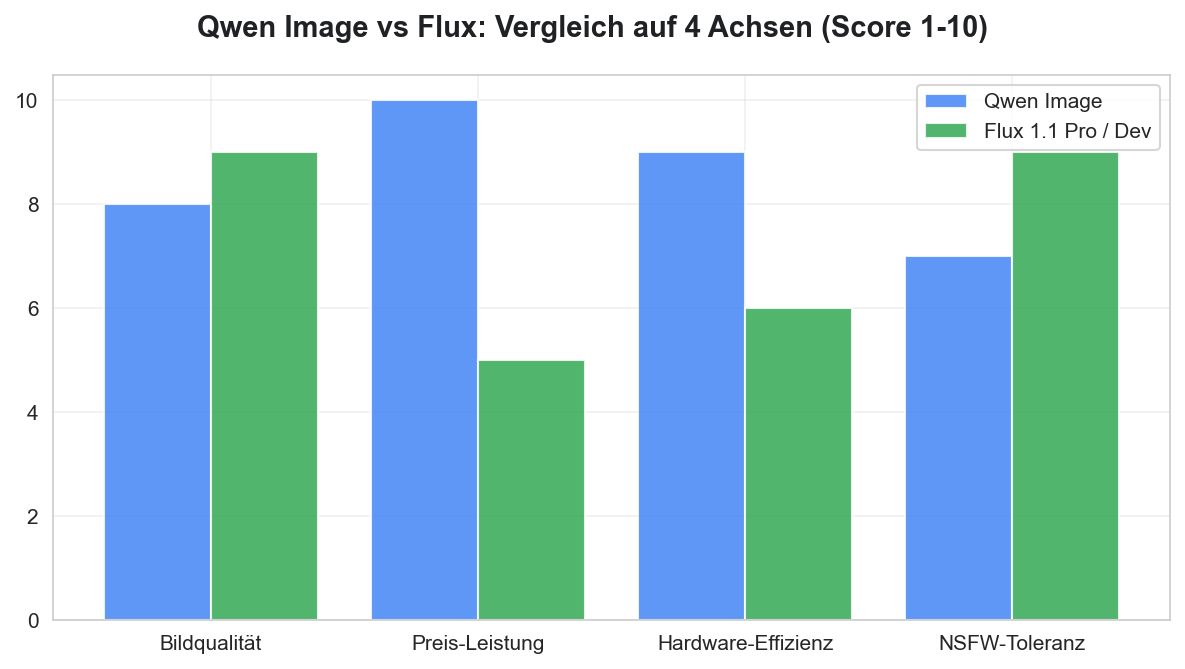
Bildqualität. Flux 1.1 Pro liegt noch leicht vorn, vor allem bei Hauttextur und feinen Details. Mit gut trainiertem LoRA und sauberem Prompt-Engineering schließt Qwen aber auf weniger als 5 % Qualitätsabstand auf — ein Abstand, den die meisten Nutzer auf Instagram oder Fanvue gar nicht mehr wahrnehmen.
Preis. Hier gewinnt Qwen klar. Bei rund 0,008 € pro Bild via Alibaba-API ist Qwen etwa fünfmal günstiger als Flux 1.1 Pro auf Replicate. Beim Self-Hosting ist beides „kostenlos“ — Qwen aber mit niedrigerer Hardware-Hürde.
Hardware-Anforderung. Qwen läuft ab 16 GB VRAM sauber, Flux Dev braucht praktisch 24 GB. Wenn du eine RTX 4080 oder ältere 3090 hast, ist Qwen oft dein einziger realistischer Self-Hosting-Pfad in die Top-Liga.
NSFW-Toleranz. Beide Open-Weights-Builds haben keine harten Filter. Flux Dev gilt aber als die etabliertere Wahl für stark monetarisierte NSFW-Pipelines (Fanvue, OnlyFans), schlicht weil das Community-Tooling (Trainings-Sets, LoRAs, ComfyUI-Workflows) reifer ist.
Empfehlung-Matrix:
- Du willst maximale Qualität ohne Preis-Limit: Flux 1.1 Pro
- Du brauchst eine günstige API für Volumen: Qwen via Alibaba
- Du hast eine 16-GB-GPU: Qwen Self-Hosting
- Du hast eine 24-GB-GPU und planst NSFW-Monetarisierung: Flux Dev
- Du willst beides parallel testen: starte mit Qwen API für die ersten 1.000 Bilder, dann entscheide
Mehr Details zum Flux-Stack findest du in unserer Flux Setup-Guide. Wenn du eher ein Plug-and-Play-Tool ohne Self-Hosting suchst, ist Nano Banana 2 die geschlossene Alternative.
FAQ
Was kostet Qwen Image? Über die Alibaba-Cloud-API rund 0,008 € pro Bild — der günstigste Managed-Preis im Top-7-Feld. Auf Drittplattformen wie Replicate liegt der Preis bei 0,015–0,025 € pro Bild. Self-Hosting ist kostenlos abgesehen von Strom oder Cloud-GPU-Miete.
Ist Qwen Image kostenlos? Ja, in zwei Varianten: Erstens ist die Web-UI auf qwen.ai gratis nutzbar, zweitens kannst du die Open-Weights von HuggingFace herunterladen und unbegrenzt lokal generieren — ohne laufende Kosten.
Erlaubt Qwen NSFW-Inhalte? Die Web-UI und die Alibaba-API filtern NSFW-Inhalte. Der Open-Weights-Build, den du bei Self-Hosting einsetzt, hat keine harten Filter — du bist hier rechtlich und ethisch selbst verantwortlich. Beachte deutsche und EU-Vorschriften (KunstUrhG, JuSchG, AI Act).
Brauche ich eine GPU für Qwen Self-Hosting? Ja. Du brauchst mindestens 16 GB VRAM für brauchbare Geschwindigkeit. CPU-Generierung ist technisch möglich, dauert aber viele Minuten pro Bild und ist in der Praxis nicht nutzbar. Wenn du keine GPU hast, miete eine bei RunPod ab rund 0,35 €/h.
Fazit
Qwen Image ist 2026 die rationalste Wahl, wenn du Kosten und Kontrolle gleichzeitig optimieren willst. Du bekommst ein open-weights Modell auf Augenhöhe mit Flux, zahlst aber einen Bruchteil des API-Preises und kommst auch mit Mid-Range-Hardware ins Self-Hosting. Für skalierte Posting-Pipelines, A/B-Tests an Prompts und Teams mit klarem Budget ist Qwen oft die beste Entscheidung.
Wenn du jetzt loslegen willst, hast du drei Wege: starte mit qwen.ai für 10 Minuten Spielerei, hole dir einen Alibaba-API-Key für die ersten 1.000 produktiven Bilder (~8 €), oder gehe direkt in ComfyUI Self-Hosting für volle Kontrolle und LoRA-Training.
Nächste Schritte:
- Vergleiche Qwen mit allen Top-Modellen in unserer Übersicht der besten KI-Bildmodelle für AI Influencer
- Lies die parallele Flux-Anleitung für den Pro-Vergleich und tiefere LoRA-Theorie
- Wenn dein Charakter bereit ist: erfahre, wie du mit deinem KI-Influencer auf Fanvue Geld verdienst


